
Hand Pose Estimation
Philip Krejov: Personal Page Andrew Gilbert: Personal Page Richard Bowden: Personal PageOverview
This work presents an approach to find each of the joints of the hand using a depth based sensor. Joint positions can then be used in a machine learning approach to assist in sign language recognition Hand joints are determined using machine learning that combines both discriminative and model based methods. This combined approch aims to overcome the limitations of each technique in isolation. The results demonstrate real-time performance and state of the art accuracy.
Motivation
Determining the joints of the hand is a very challanging problem, consideration must be given to the following.
- The large range of arm motion allows for large variety in hand poses.
- Hands are comprised of a complex chain of kinematic relationships, and this flexibility can cause large scale occlusion and deformation.
- Because the hands form only a small portion of the image, there is limited resolution for examining the hand.
Method
The combined decent method aims to utilise the strengths of both discriminative and model based approaches. The discriminative method is used as a global approximation, using a Randomised Desition Forest (rdf) trained using labelled depth data. This provides a coarse estimate of the pose that is fast to acqurie. Next a model based approach is fitted to this observation. Rather than search multiple states as with other approches, our aim is to optimise only a single model using a data driven approach. Fitting using result of the RDF, greatly reduces run time. Effectively guiding the search closer to the global optimal. This reduces the complexity of optimisation as the forests segmentation is a far less ambiguous than depth alone. The model is optimised using Articulated Body Dynamics and is posed in a physics driven framework. This means tracking is handled implicitly by the simulation. A final regression stage is then used to characterise the failure cases and provide additional constraints, improving performance further.
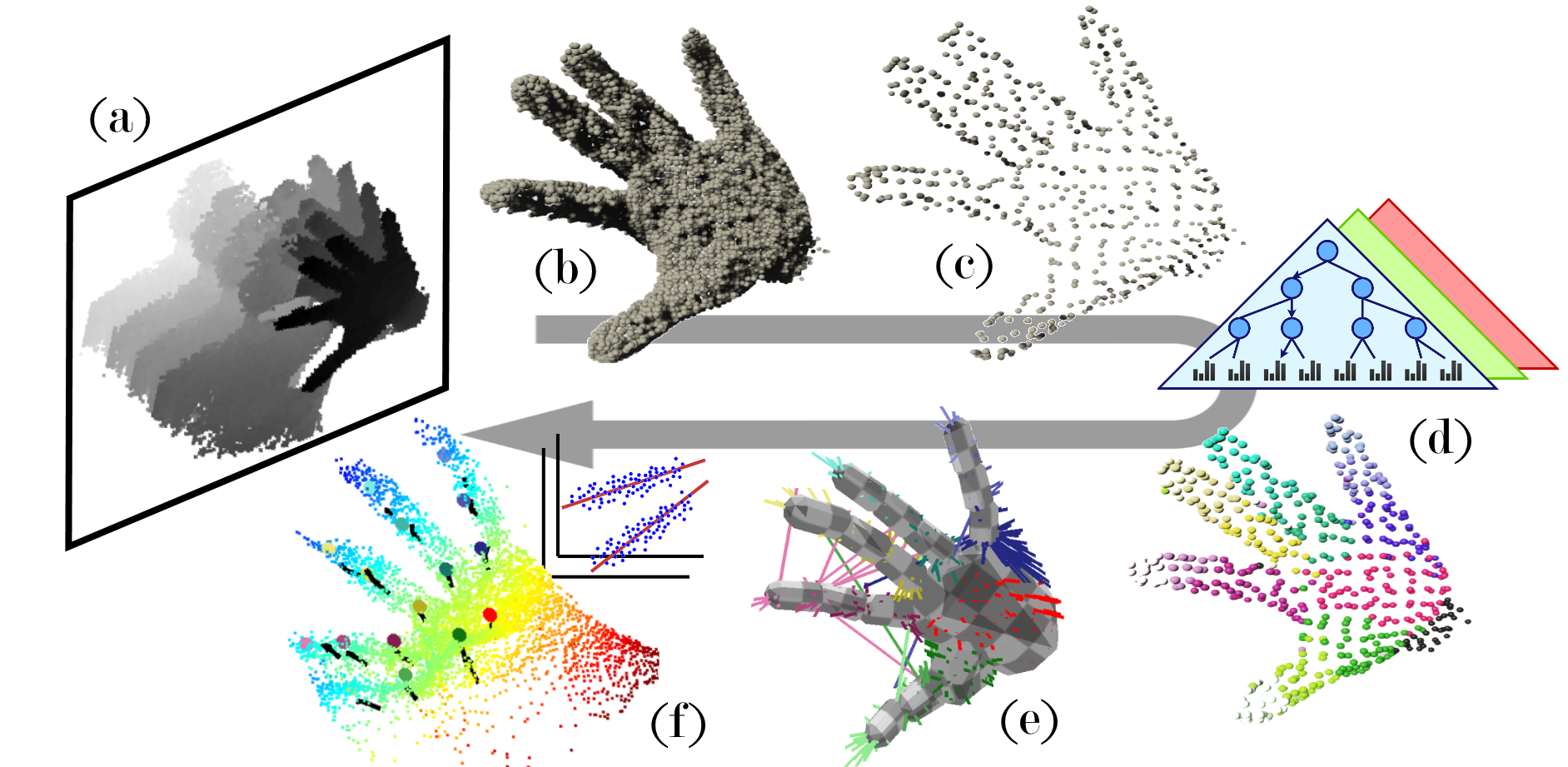
Method overview which shows processing of the depth camera stream. (a,b,c) The depth is converted to its corresponding point cloud for filtering and sub-sampling. (d) Forest classification labels each point using depth. (e) This provides correspondence for constraint-driven optimisation. (f) Linear regression using depth sampled features then corrects model discrepancies.
Results
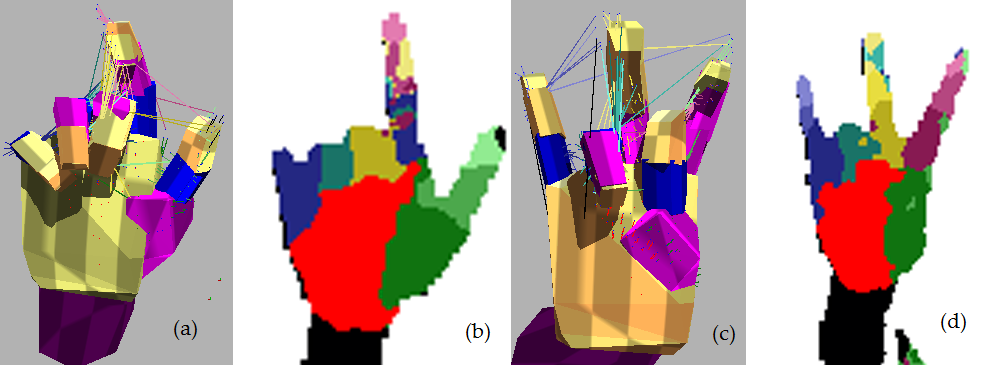
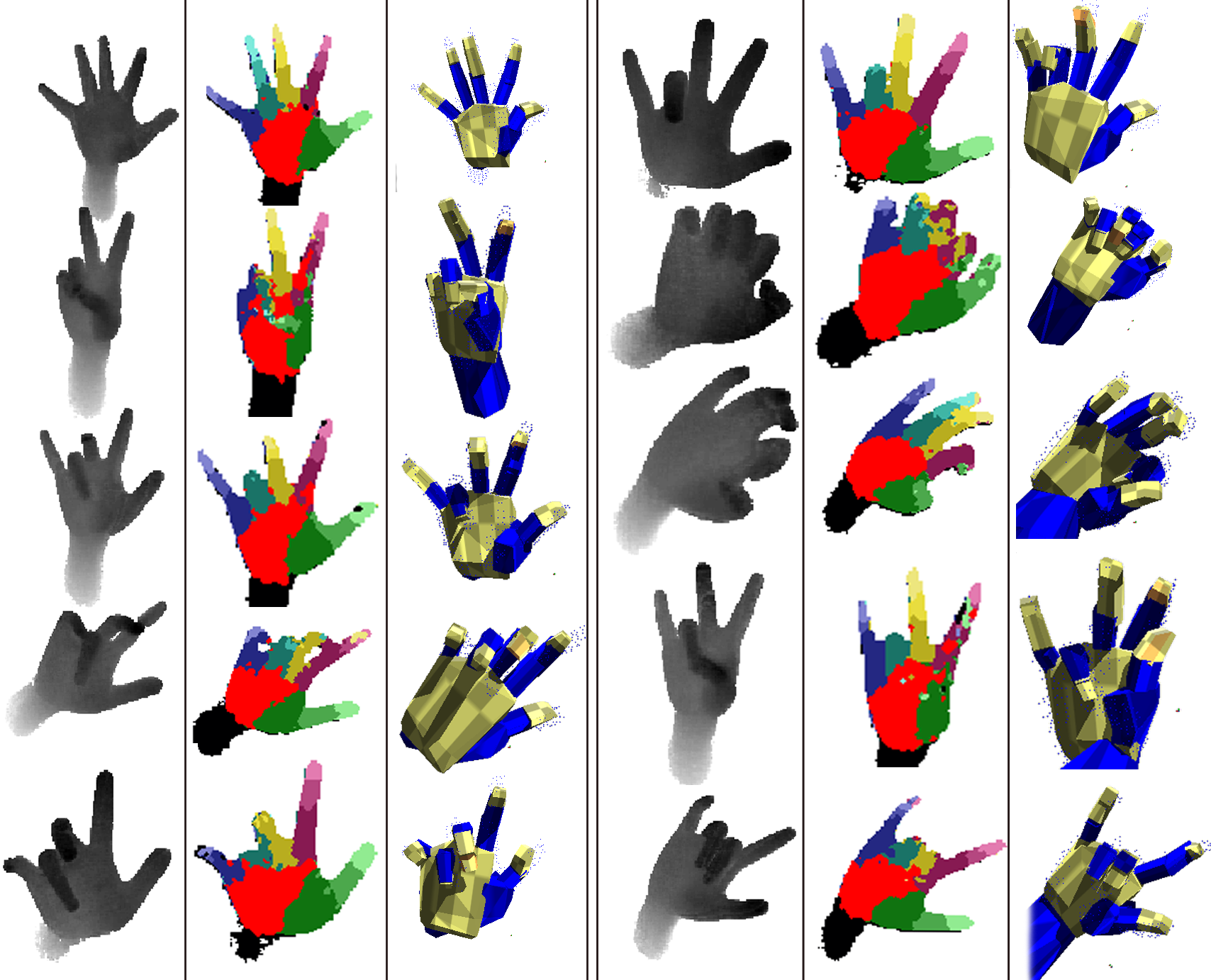
The images (a) & (c) show the result of model convergence based on the classification output in the images (b) & (d) respectively. The classification of the first pose shows confusion in labelling the index finger, which without the use of our second stage refinement would be incorrectly determined. The same issue can be seen in the index and middle finger in image (d)
Video demos of our earlier related work
Publications
Combining Discriminative and Model Based Approaches for Hand Pose Estimation.
In International Conference on Automatic Face and Gesture Recognition, IEEE, 2015.
Multi-Touchless Interfaces: Interacting beyond the screen.
In IEEE Computer Graphics and Applications, CG&A, Vol 34(3), 2014, pp40-48..
Download: [bib] [pdf] Project page
Multi-touchless: Real-Time Fingertip Detection and Tracking Using Geodesic Maxima
In International Conference on Automatic Face and Gesture Recognition, IEEE, pp. 7, 2013.
Download: (dataset) [bib] [pdf] Project page
Acknowledgements
This work was part of the EPSRC project “Learning to Recognise Dynamic Visual Content from Broadcast Footage“ grant EP/I011811/1.